

Sample Research Questions
•
How can regression techniques be used to explain the relationship between and ?
•
Predicting the value based on multiple input factors , , ?
•
How can interpolation methods can be used to generate the simplest possible curve passing through data points?
How can [Regression Technique] be used to explain the relationship between [explanatory variable #1, #2, #3...] and [dependent variable]
Linear Regression
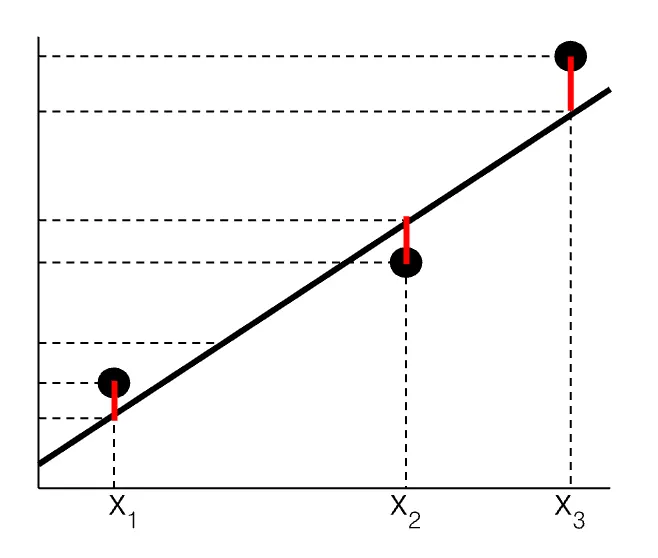
Suppose we have non-collinear data points, , ,…,.
A linear regression model, , may be defined to predict a value of for each corresponding input value of .
Depending on how the line is drawn, some predicted values are less than the actual value .
and underestimate the value of and respectively.
In other cases, the predicted value of is greater than the actual value of .
, for example, overestimates the value of .
Given that an infinite combination of coefficients are possible, which linear equation would be the curve of best fit offering the most accurate representation of all individual data points?
Key Questions
•
Is there a metric that quantifies and compares how closely linear regression models fit over a set of data points?
•
Should the regression model prioritize fitting certain data points more closely than others or should it aim to minimize the overall error across all data points?
Sum of Squared Errors (SSE) is a collective measure of error that penalizes both positive and negative deviations from all data points equally.
Linear Regression seeks to find the set of coefficients that minimizes SSE
Minimize
Investigation:
Find such that:
is minimized.
The optimal solution, , provides coefficients for line of best fit that minimizes SSE.
Extension:
•
What other loss functions, other than SSE, can be used to penalize deviations of the model from data points to guide the optimal selection of model parameters ?
•
What if more complex, non-linear regression models like promise a better fit?
Polynomial Interpolation
Extending the previous discussion of linear regression models in the form, ,
the polynomial interpolation method finds a polynomial function that fits a set of data points exactly.
Polynomial Interpolation Theorem
Given any points, , ,…,, in the -plane with distinct -coordinates such that , there is a unique th degree polynomial passing through each of these points.
Substituting known pairs of ’s and ’s that the polynomial function passes through, the following system of equations must be satisfied:
…
Investigation
Find a cubic polynomial function whose graph passes through these four points:
, , ,
Solve system of equations to find coefficients:
Extension:
•
Systematic approaches to reliably obtain solutions to large systems of equations with equations and unknown variables (in the HL syllabus, we typically worked with , )
•
Lagrange polynomial interpolation
Equivalently, we can use product notion:
•
Newton polynomial interpolation
•
Could we perform regression (curve fitting) for more than one independent variables?
Multiple Linear Regression
For a bivariate data set, regression equations modelled as a single variate function of .
For multivariate data sets, a multitude of input variables are mapped to one composite output.
X2 | |||
Loss Function (SSE)
Similarly to classic linear regression, define a sum of squared error (SSE) metric loss function that penalizes deviations between the actual value of and the predicted value of .
Apply partial differentiation to solve for the optimal selection of coefficients that minimize the loss function, .
For ,
Partial Differentiation
Similar to the condition, setting the partial differentiation to zero is a technique used for optimization, but for multivariate functions.
Investigation
Minimizing loss function with respect to gives rise to the least squares normal equations.
Extension
•
What are some real life situations or problems that invite the appropriate use of multiple linear regression?
•
How can we incorporate non-linear terms into multiple linear regression models?